Apache Druid
What is Apache Druid?
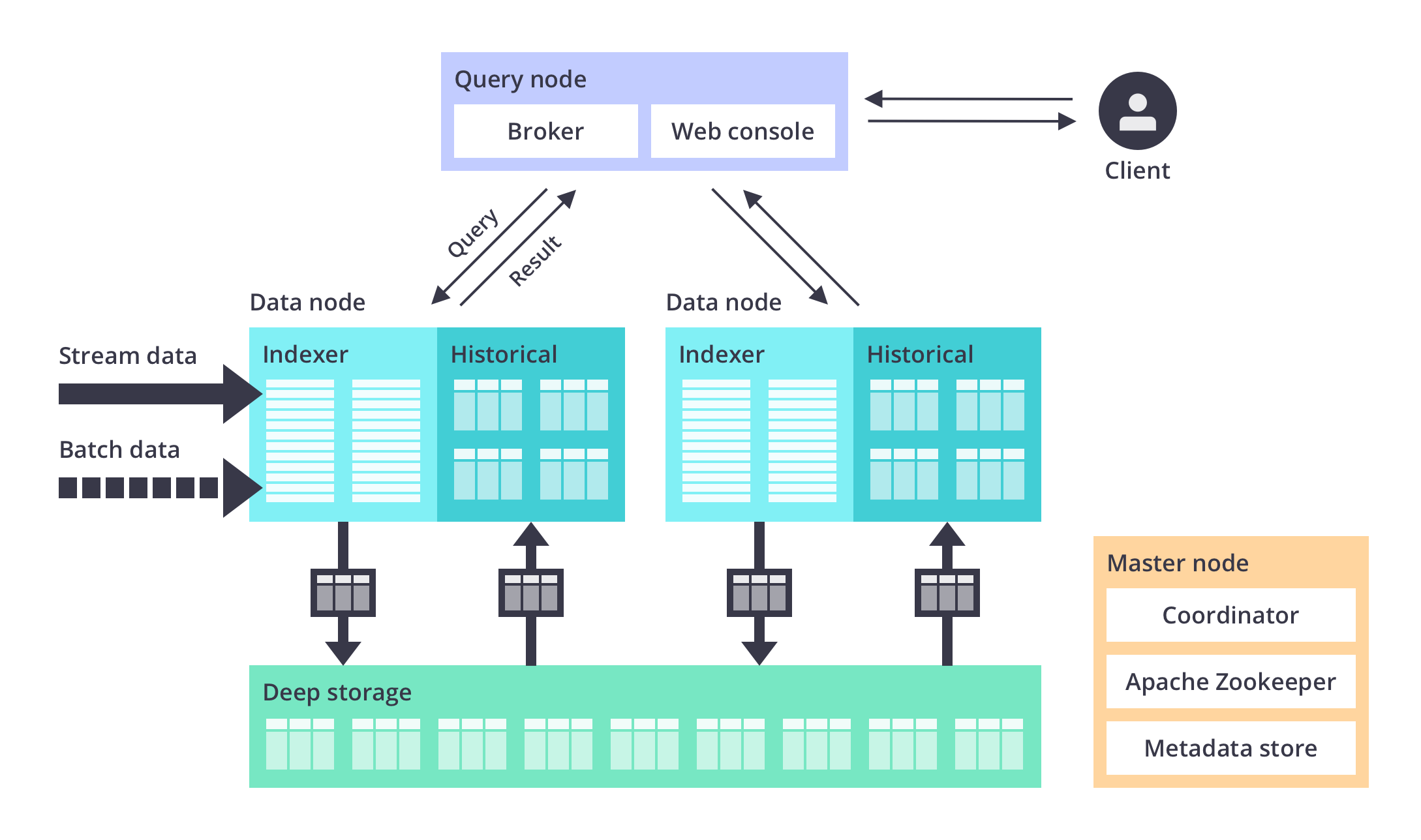
Druid High Level Architecture
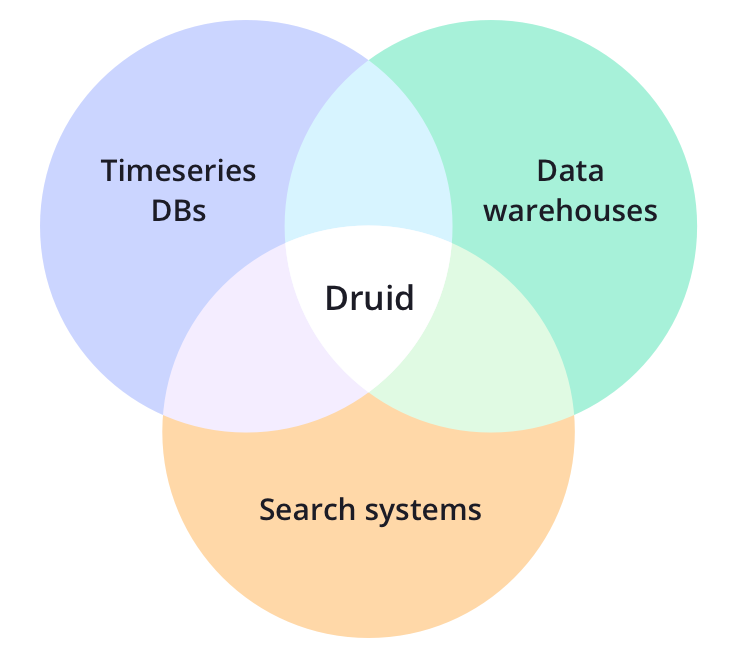
Druid’s core design combines ideas from data warehouses, timeseries databases, and search systems to create a high performance real-time analytics database for a broad range of use cases. Druid merges key characteristics of each of the 3 systems into its ingestion layer, storage format, querying layer, and core architecture.
Druid Features
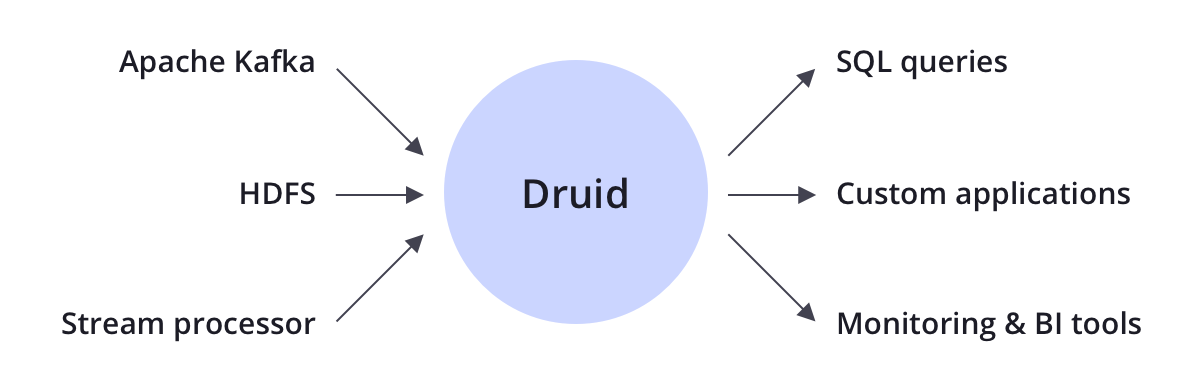
Druid: Integration
Druid is complementary to many open source data technologies in the Apache Software Foundation including Apache Kafka, Apache Hadoop, Apache Flink, and more.
Druid typically sits between a storage or processing layer and the end user, and acts as a query layer to serve analytic workloads.
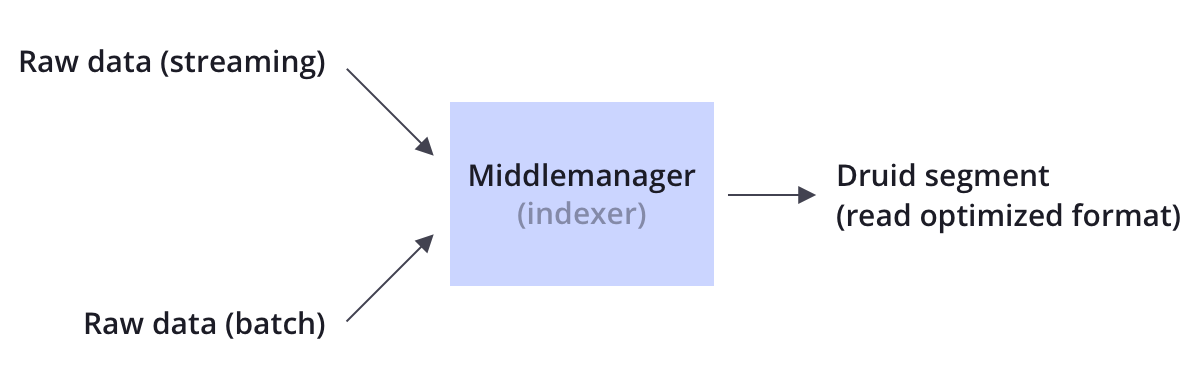
Druid: Ingestion
Druid supports both streaming and batch ingestion. Druid connects to a source of raw data, typically a message bus such as Apache Kafka (for streaming data loads), or a distributed filesystem such as HDFS (for batch data loads).
Druid converts raw data stored in a source to a more read-optimized format (called a Druid “segment”) in a process calling “indexing”.
Druid: Storage
Druid: Pre-aggregation
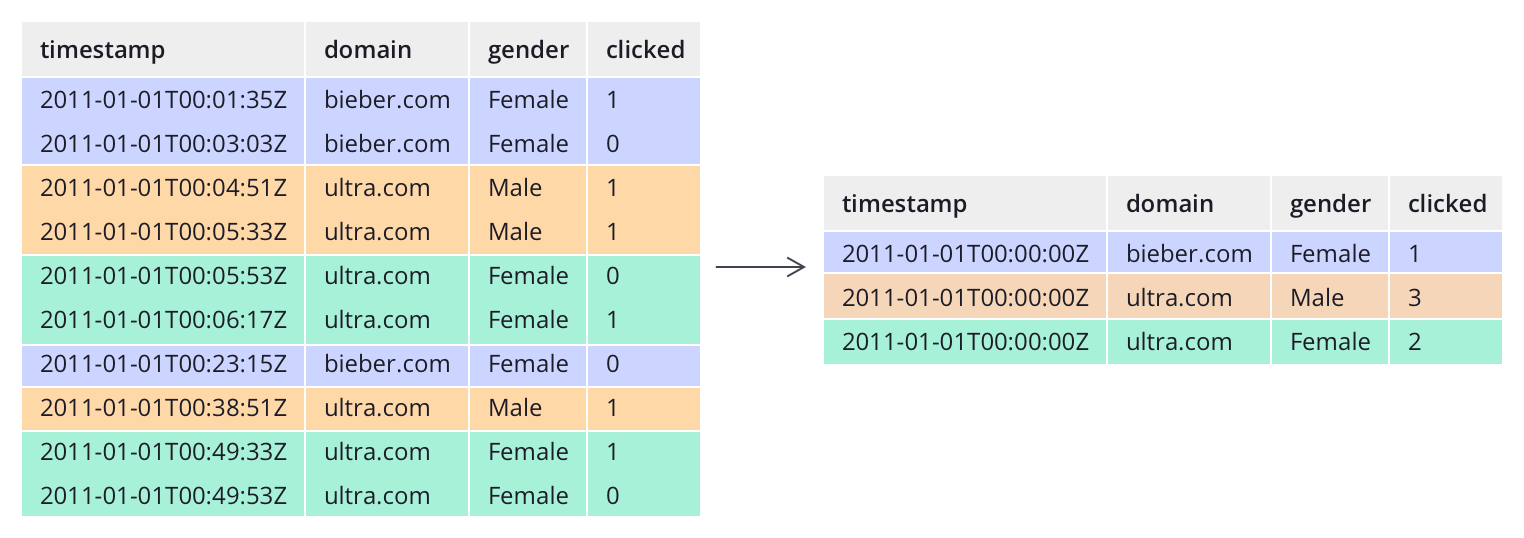
Unlike many traditional systems, Druid can optionally pre-aggregate data as it is ingested. This pre-aggregation step is known as rollup, and can lead to dramatic storage savings.
Druid: Querying
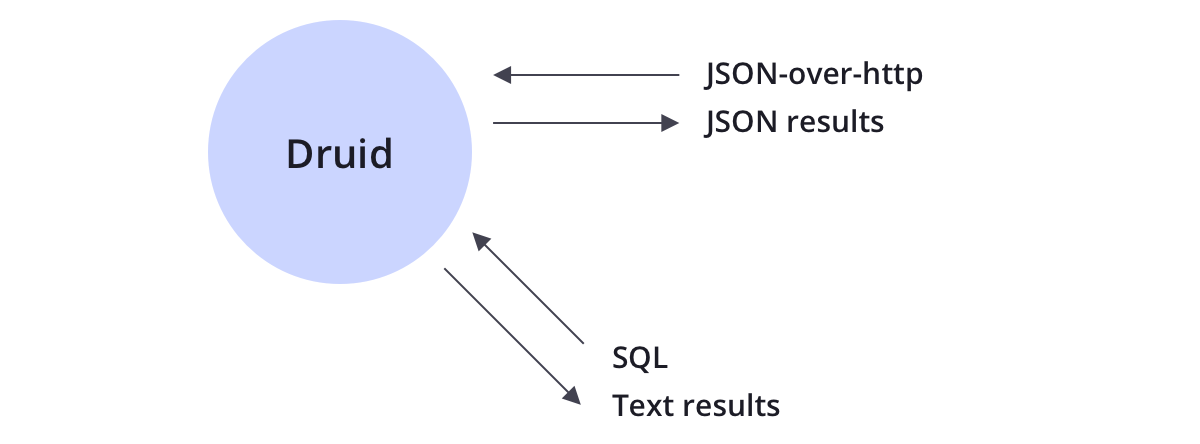
Druid supports querying data through JSON-over-HTTP and SQL. In addition to standard SQL operators, Druid supports unique operators that leverage its suite of approximate algorithms to provide rapid counting, ranking, and quantiles.
Druid: High Level Architecture Diagram