What is Apache Flink?
Apache Flink is a framework and distributed processing engine for stateful computations over unbounded and bounded data streams. Flink has been designed to run in all common cluster environments, perform computations at in-memory speed and at any scale.
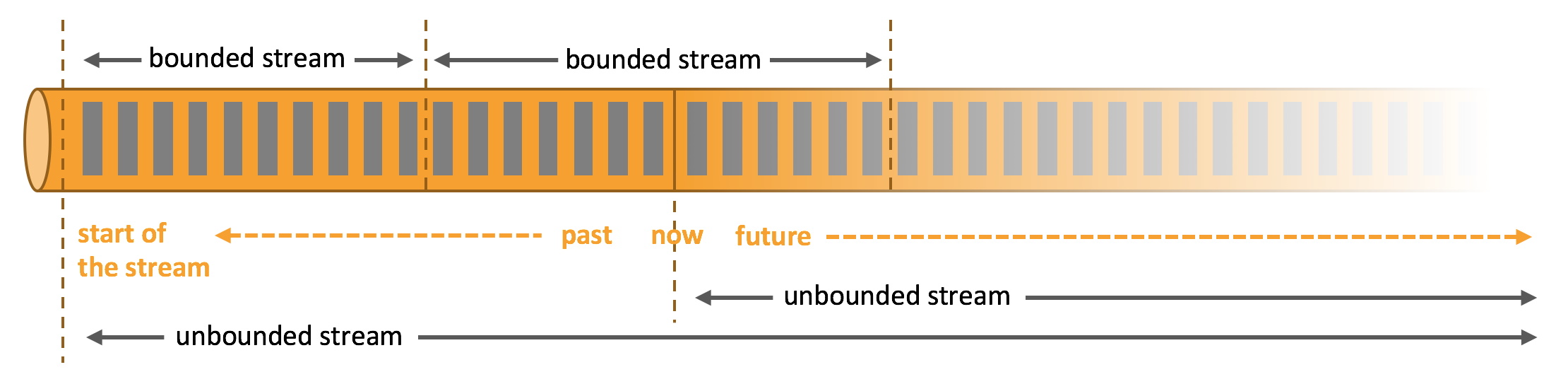
Unbounded and Bounded Streams
Apache Flink supports both unbounded and bounded streams:
Unbounded streams have a start but no defined end. They do not terminate and provide data as it is generated.
Bounded streams have a defined start and end. Bounded streams can be processed by ingesting all data before performing any computations. Processing of bounded streams is also known as batch processing.
Deploy Applications Anywhere
Run Applications at any Scale
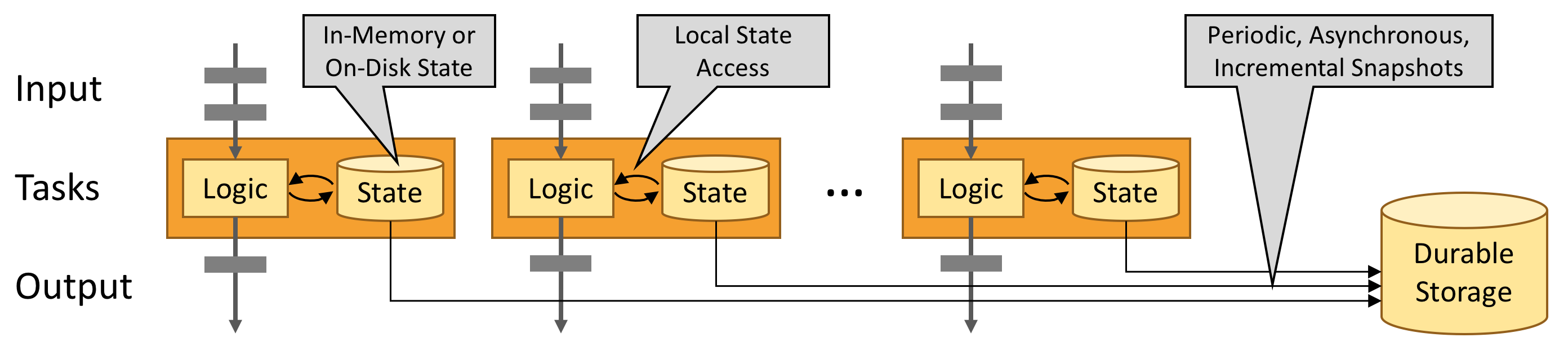
Leverage In-Memory Performance
Stateful Flink applications are optimized for local state access.
Task state is always maintained in memory.
If the state size exceeds the available memory, it is maintained in access-efficient on-disk data structures.
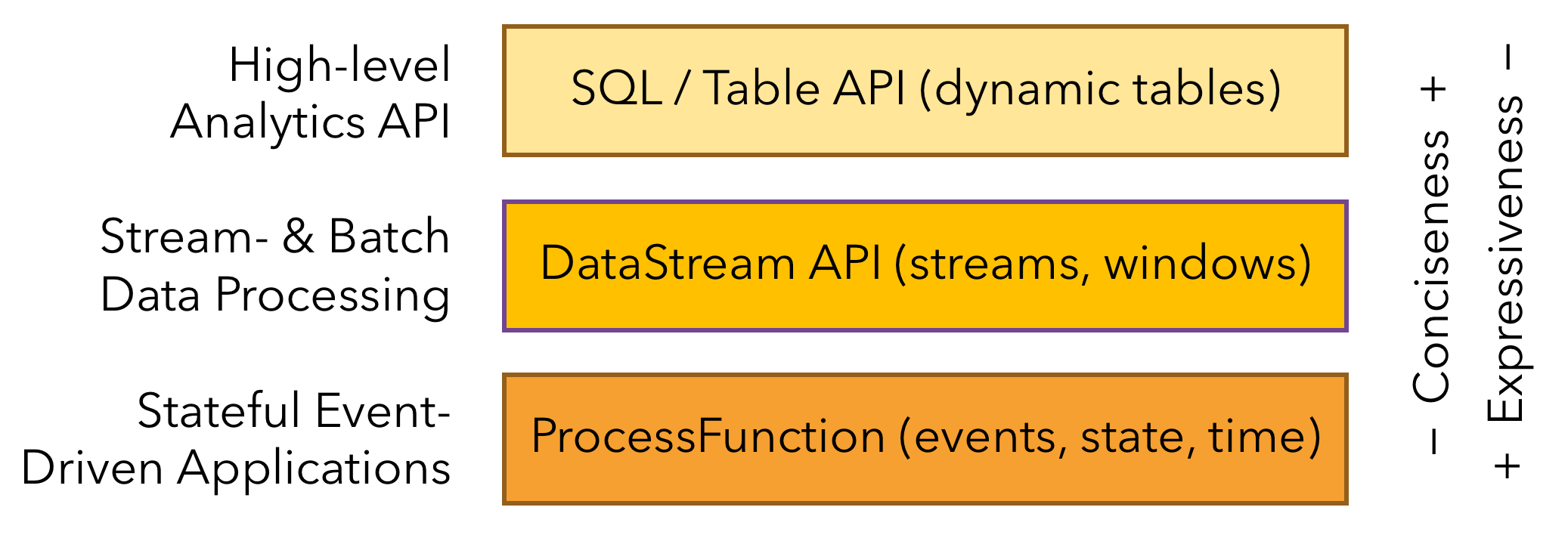
Layered APIs in Apache Flink
Flink provides three layered APIs. Each API offers a different trade-off between conciseness and expressiveness and targets different use cases.