What is Apache Samza?
Apache Samza is a distributed stream processing framework. Samza allows to build stateful applications that process data in real-time from multiple sources including Apache Kafka. Samza is battle-tested at scale, it supports flexible deployment options to run on YARN or as a standalone library.
Samza High Level Architecture
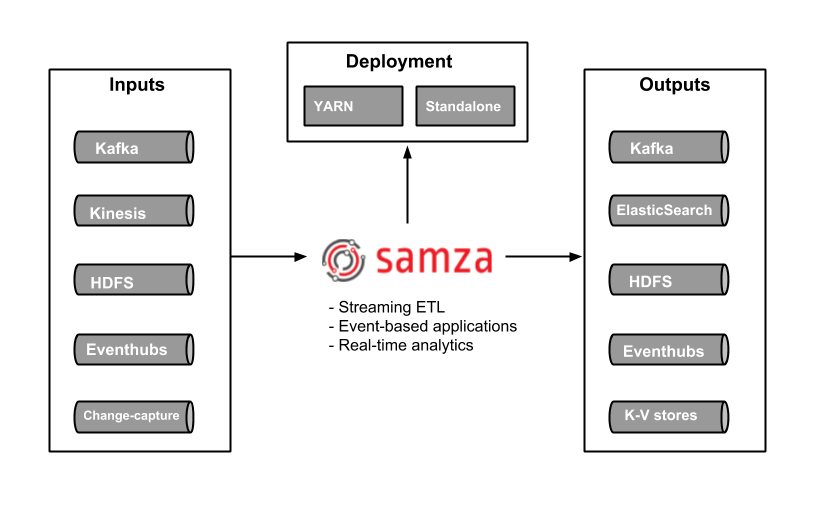
Samza Features
Samza: Unified API
Samza: Pluggability at every level
Samza: An embedded library
Samza: Write once, Run anywhere
Samza: As a managed service
Samza: Fault-tolerance
Samza: Massive scale
Samza: Streams
Samza processes the data in the form of streams.
A stream is a collection of immutable messages, usually of the same type or category.
Each message in a stream is modelled as a key-value pair.
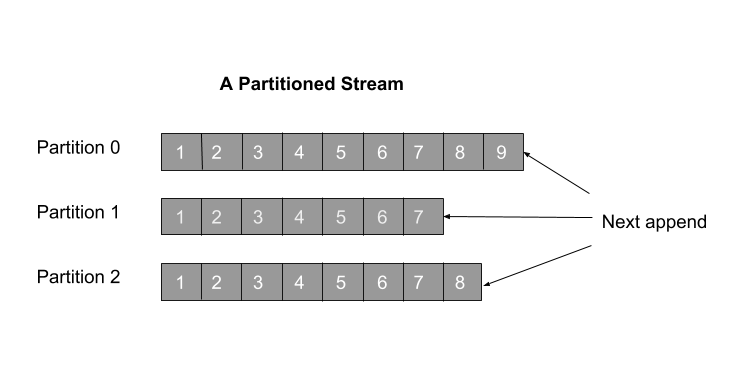
Samza: Partitions
Samza State vs. Stateless
Samza Processing Time
Samza Processing guarantee
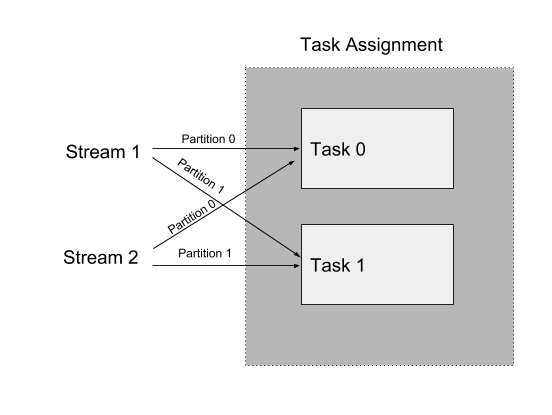
Samza Task Execution
Samza Task Execution Diagram
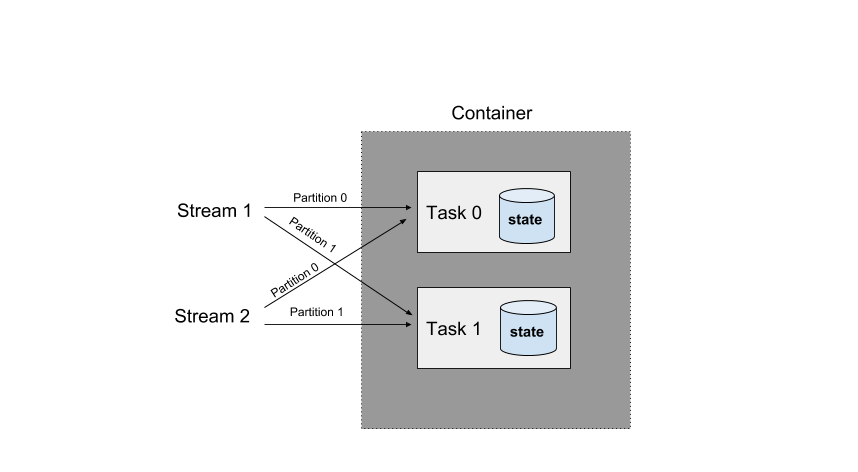
Samza Container
Samza Container Diagram
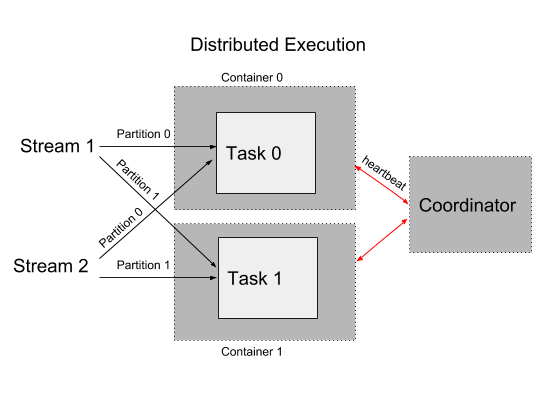
Samza Coordinator
Samza Incremental Checkpointing
Samza Incremental Checkpointing Diagram
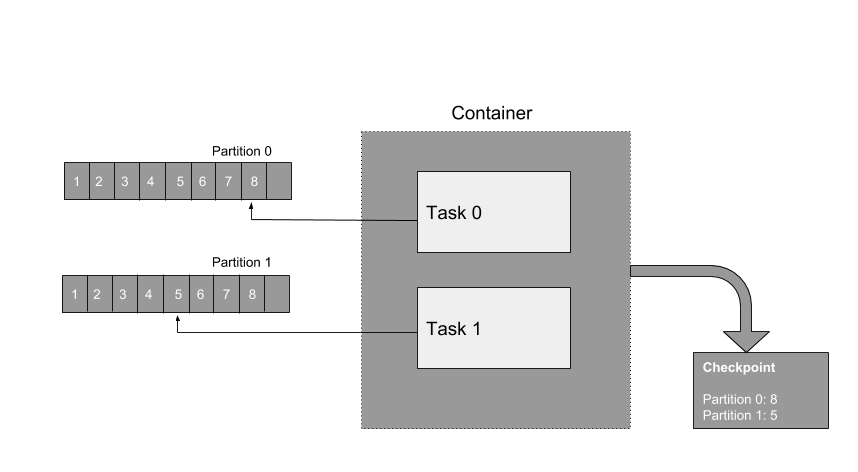
Samza State Management
Samza State Management Diagram