
Introduction
ZooKeeper is a distributed, highly available, scalable and strictly consistent hierarchical data store
Introduction
Current version is 3.5.5 (May 2019)
Released after five years of development
Major new features: Dynamic Reconfiguration, "container" znode, more later
Other maintained branch is 3.4 with 3.4.14 (April 2019)
One of the first tools from the Hadoop ecosystem
Built at Yahoo!, now an Apache project
Use Cases
Foundation for many features in the Hadoop ecosystem
HA (HBase, YARN, Hive, …)
Coordination (HBase, …)
"Recipes" easily implemented using ZooKeeper:
Group Membership, Name Service, Configuration, Barriers, Queues, Locks, Leader Election, Two-phased commit
While ZooKeeper originated within the Hadoop ecosystem it is used heavily outside of it as well
e.g. Solr and others
Data Model
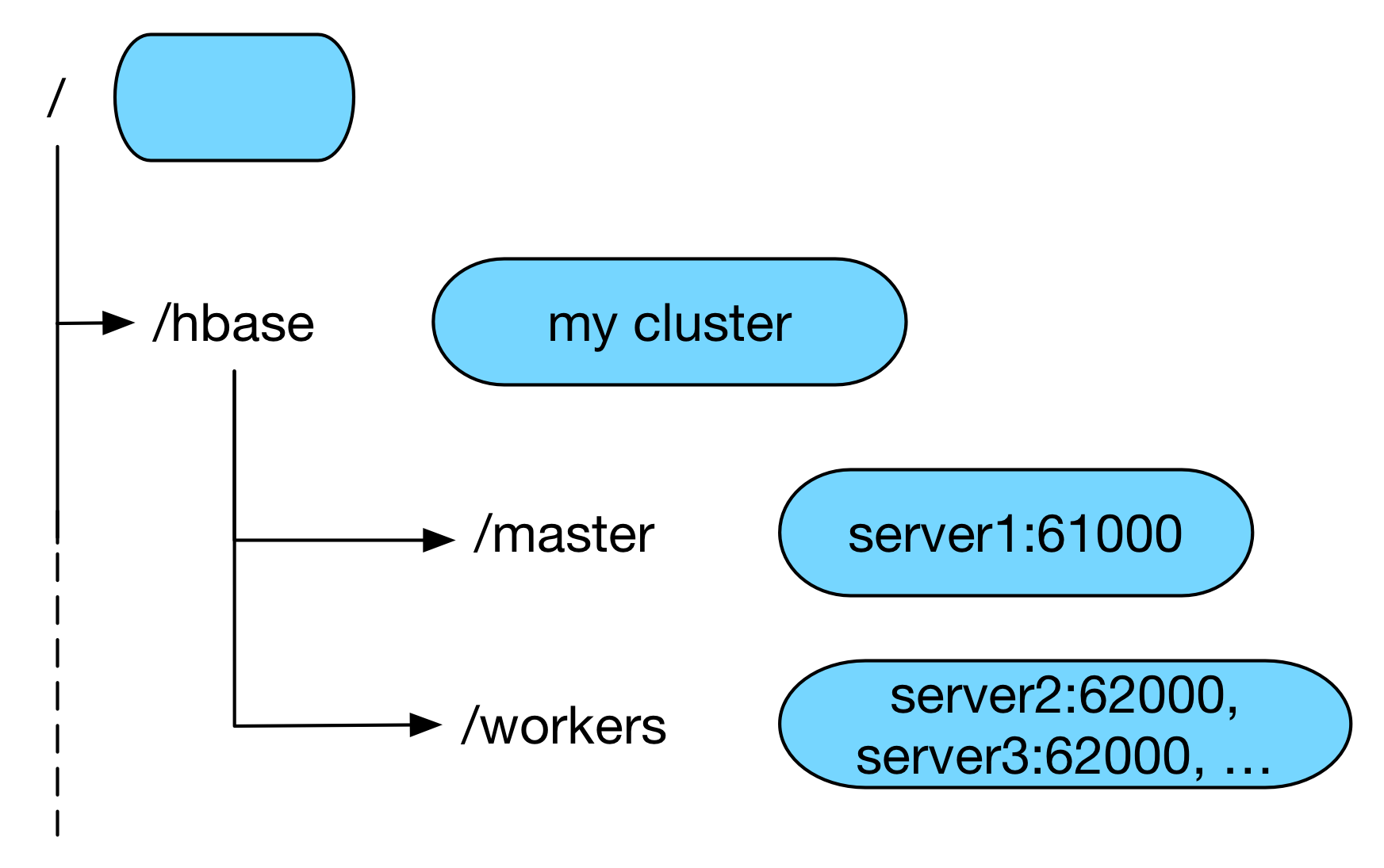
Data Model
Hierarchy of nodes (called znode)
Similar to typical file systems
Each node can "contain" other nodes as well as data
Different from file systems where a node is either a file or a directory
Data in a node is usually small
In the kilobyte range
Data Model
As all updates are strictly ordered, and only a single master process performs writes, ZooKeeper is not meant as a high-volume data
ZooKeeper knows several different types of nodes
A connection to ZooKeeper is called a "session" and is also assigned an id
Connection setup is relatively expensive because it also requires a quorum/vote
znodes can be watched (i.e. notifications on changes)
Node Types
Ephemeral nodes
Ephemeral nodes get deleted automatically once the session is closed in which it was created
Can be used to get notified of failed servers (using watches)
Persistent nodes
These will not be deleted when the session ends
Node Types
Time to live (TTL) nodes (as of 3.5)
When creating a node a TTL value (in ms) can be specified
When the node has not been modified within the TTL and there are no children it may also be deleted automatically
Container nodes (as of 3.5)
When all child nodes have been deleted the container node may also be deleted automatically at some point
Node Types
Ephemeral, Persistent and TTL nodes can additionally be sequential
This will automatically append a monotonically increasing number to the end of the node name
Implementation Details
ZooKeeper uses a wire protocol based on a library called "Jute"
Extracted from Hadoop
Not used outside of ZooKeeper
There are native clients for C and Java
Other (e.g. Python) clients maintained by the community
Apache Curator is a Java based client library that is often easier to use than the native one as it offers higher level concepts
Zab Protocol
ZooKeeper is a distributed system to store data
It needs a way for multiple servers to agree on any changes to the data/state
This is where the "Zab" protocol comes in
Zab Protocol
ZooKeeper can use multiple servers in what’s called an "Ensemble"
Zab is an algorithm to guarantee reliable delivery, total and causal order of messages in the face of unreliable networks
To put it differently: It is a protocol for a bunch of servers to agree on a value
In an ensemble there is at most one leader server supported by a quorum
On Votes
ZooKeeper sometimes uses the term vote which implies a choice
In reality the servers don’t have a choice but just need to acknowledge a change
This is similar to a two-phase-commit protocol
Sidebar: Quorum
ZooKeeper is heavily based on the concept of a "quorum"
It has two implementations to determine the quorum
Majority
Hierarchical
Sidebar: Majority Quorum
This is the default and pretty simple
All voting servers get one vote
Not all servers vote (more on this later)
Quorum is achieved once more than half (i.e. majority) of the voters have acknowledged a write
Example: An ensemble of 9 voting servers requires votes from 5 of those servers to succeed
Sidebar: Hierarchical Quorum
Servers can belong to a group
And servers have a weight (default: 1)
Quorum is obtained when we get more than half of the total weight of a group for a majority of groups
Example:
9 servers, 3 groups, weight of 1 for each
This requires two group majorities to obtain quorum
Each group requires a weight of 2 (i.e. 2 servers) to achieve quorum
In total 4 votes are required to achieve quorum
Sidebar: Hierarchical Quorum
This is a rarely used feature
More information can be found in ZOOKEEPER-29
The original idea was to use this across (physical) locations on the assumption that failures were more likely to be correlated with a location going down than a single instance
Zab Protocol
All voting servers elect a leader
Leader is the one with the most votes (i.e. majority or quorum)
For this reason usually an odd number of servers
All servers can serve read requests but all write requests are forwarded to the Leader
Clients can talk to any server (without having to know its current role), requests are forwarded appropriately
Scaling
All changes in the system are voted upon (coordinated by the Leader)
The more servers there are the longer this process takes
Hence the concept of "participants" and "observers" exists
Participant servers take part in votes
Observers are non-voting member which only hear the results of votes
This allows ZooKeeper to scale more easily without sacrificing performance
Scaling
Dynamic Reconfiguration
Before 3.5 the membership of the ensemble and all configuration parameters were static, a restart was required to change this
Starting in 3.5 this (and more) can be changed dynamically without requiring restarts
Resources
Links to detailed descriptions of the Zab protocol